GitHub WebHooks and Jenkins go together like peanut butter and jelly.
SCM Webhook trggers are way more efficient for Jenkins over SCM polling. Webhooks also give you a great UX – Jenkins reacts
immediately when you push a commit or open a pull request.
I am a huge fan of using GitHub OAuth for single sign on with Jenkins.
The security of OAuth really depends on TLS/SSL for protecting the token in transit,
so your Jenkins should use SSL when using GitHub OAuth.
GitHub’s Webhooks have the option to perform SSL certificate validation. I’ve
run into issues with GitHub’s “Hookshot” HTTP engine failing SSL verification for
otherwise valid certificates. Most of my problems were related to installing
intermediate CA certificates on Jenkins.
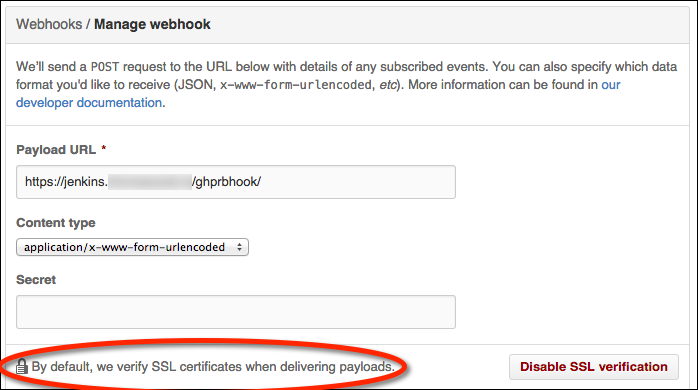
GitHub WebHook configuration and SSL certificate verification
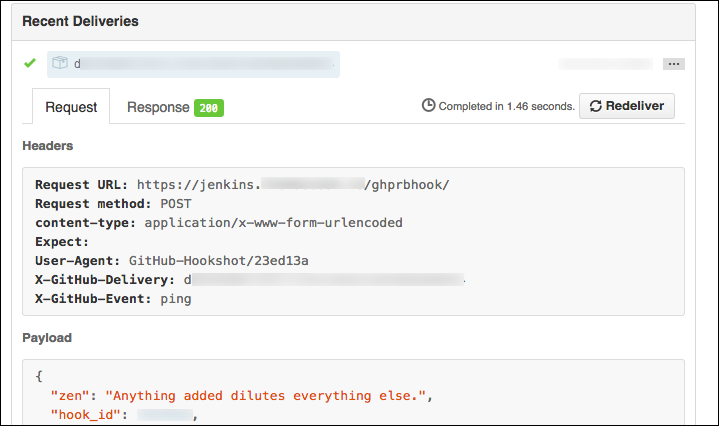
Here’s an example of a pull request webhook failing SSL validation in GitHub:
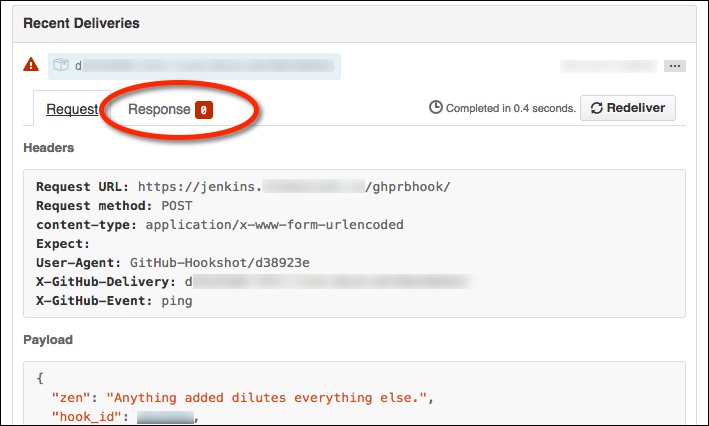
GitHub will send a “hello, world” webhook ping when you create a new webhook. Note
that SSL verification failures will have an usual HTTP response code of 0:
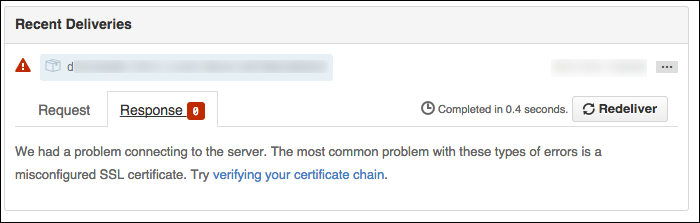
The response tab will be empty:
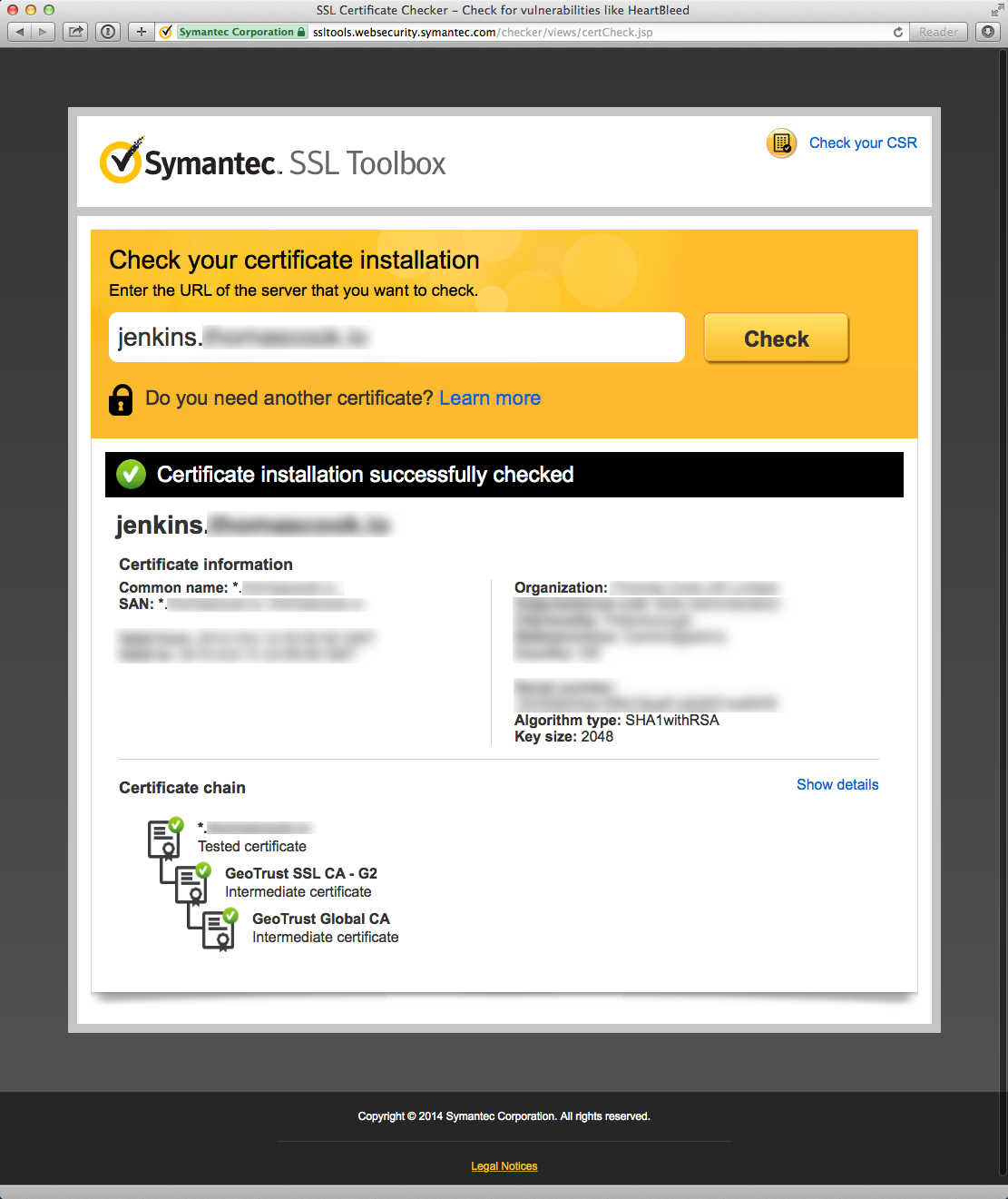
Troubleshoot your SSL certificate with the Symantec SSL Toolbox
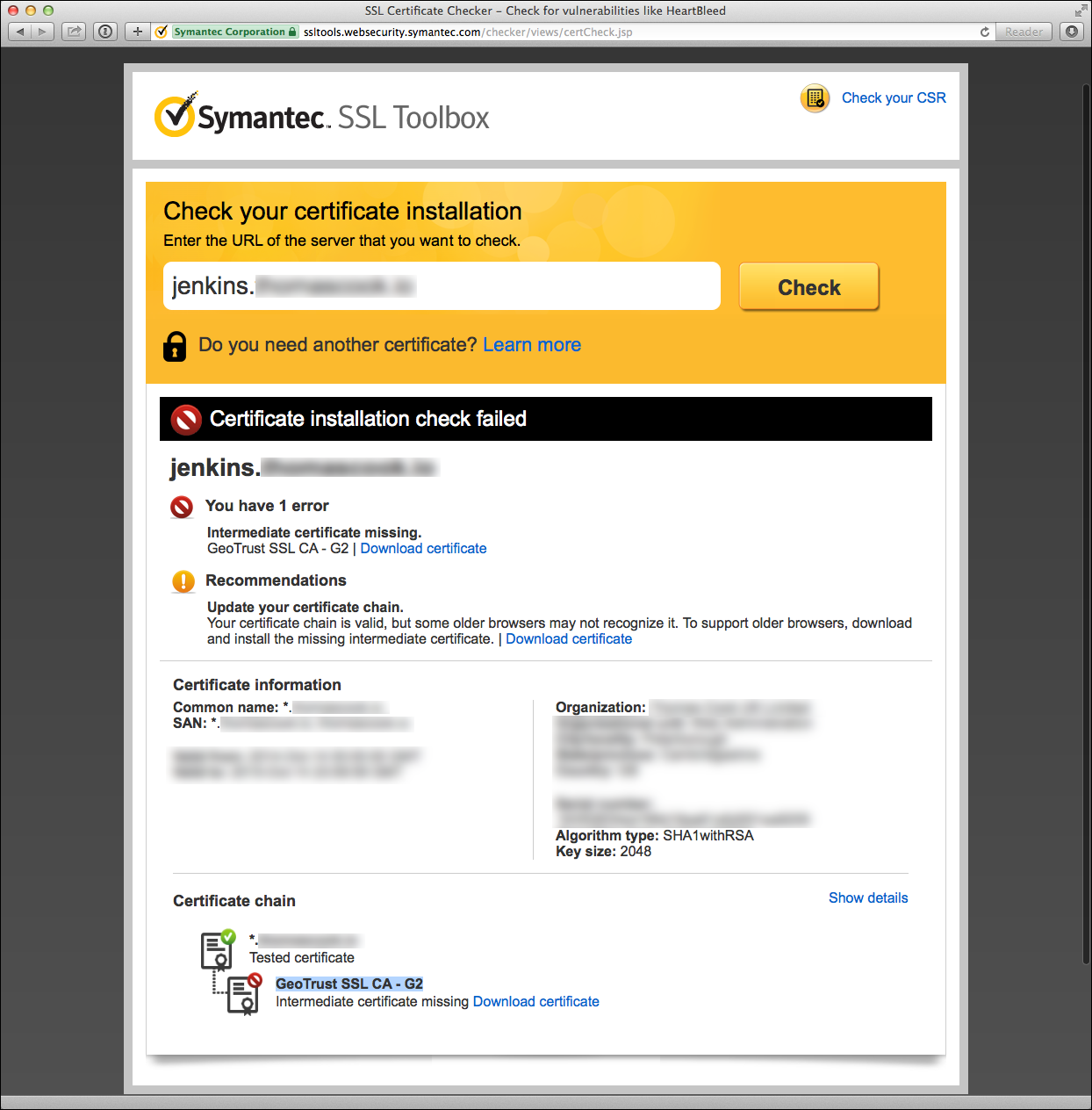
Symantec offers a very helpful tool to check your certificate installation
as part of their “SSL Toolbox”. The tool offers suggestions to remedy certificate
issues and links to download missing intermediate CA certificates.
Here’s an example of a Symantec diagnostic failure due to a missing intermediate certificate:
Using the Symantec SSL Toolbox against servers with IP ACLs
A great feature of the Symantec SSL Tool is how the tool supports non-public servers
behind a firewall. The tool will first attempt to verify your cert from
a Symantec server. If your server is behind a firewall that denies public access
except for whitelisted origins, the SSL toolbox has a fallback mode to run a Java applet
in your browser. The applet will perform the SSL verification
requests from local machine rather than a Symantec server.
TIP: GitHub publishes their public IP range for webhooks as part of the
GitHub metadata API if you wish to create firewall
whitelist rules for GitHub webhook requests.
Symanetc SSL Toolbox Applet and OS X Java security
Given the recent security vulnerabilities of Java applets, getting the applet to run
on OS X takes some work. Here are the setting I need to use the applet in Safari 7.1
on OS X 10.9.5 (Mavericks) using the Oracle/Sun JRE 1.7 R71.
(I never succeeded in using the applet in Firefox or Chrome despite serious effort.)
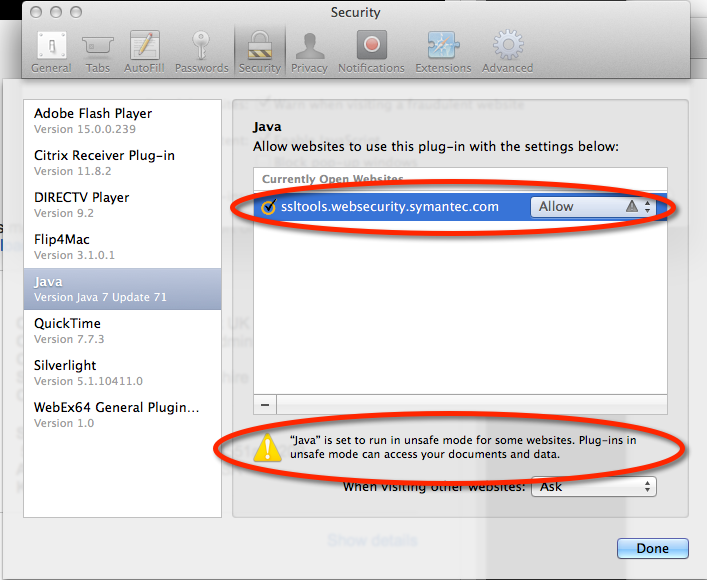
I needed to enable Safari to run the SSL Toolbox applets in “unsafe mode” without prompting:
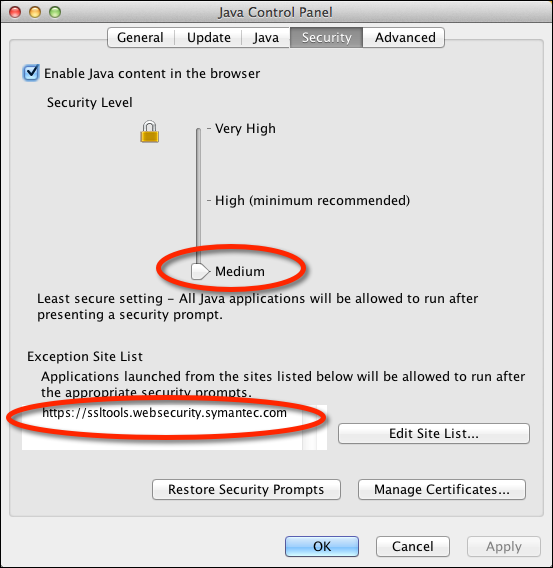
I also had to temporarily downgrade the JVM 1.7 browser security level to “Medium” and
add an execption for https://ssltools.websecurity.symanttec.com:
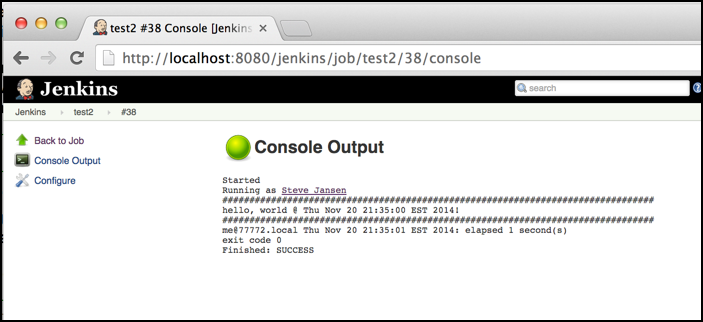
Green is good!
Once you’ve resolved your certificate issues, you should see green in both the
Symantec SSL Toolbox and the GitHub WebHook requests after enabling SSL verification.